Modelling Spelling Variations in Slavic for Textual Research
Danslav Slavenskoj
Whenever it becomes necessary to perform an automated work that spans multiple Slavic languages, or the historic axis of even one language, one becomes confronted with the issue of spelling, dialectical, and stylistic scribal variations. This concept was clearly illustrated in 1958 by R. I. Avanesov and S. B. Bernshtejn with the use of a vector diagram, centred in the present, and allowing for dialectical, historic, and stylistic vectors, among others, which can then be modelled according to known linguistic patterns (AVANESOV, 1958). What the authors did not anticipate in 1958, however, was that these variations can be modelled algorithmically, nor, perhaps were they aware of the vast amounts of data that corpus based approaches bring to the table, making such tools necessary. We have attempted to begin programmatically modelling the variations described, as well as others, across all Slavic languages algorithmically.
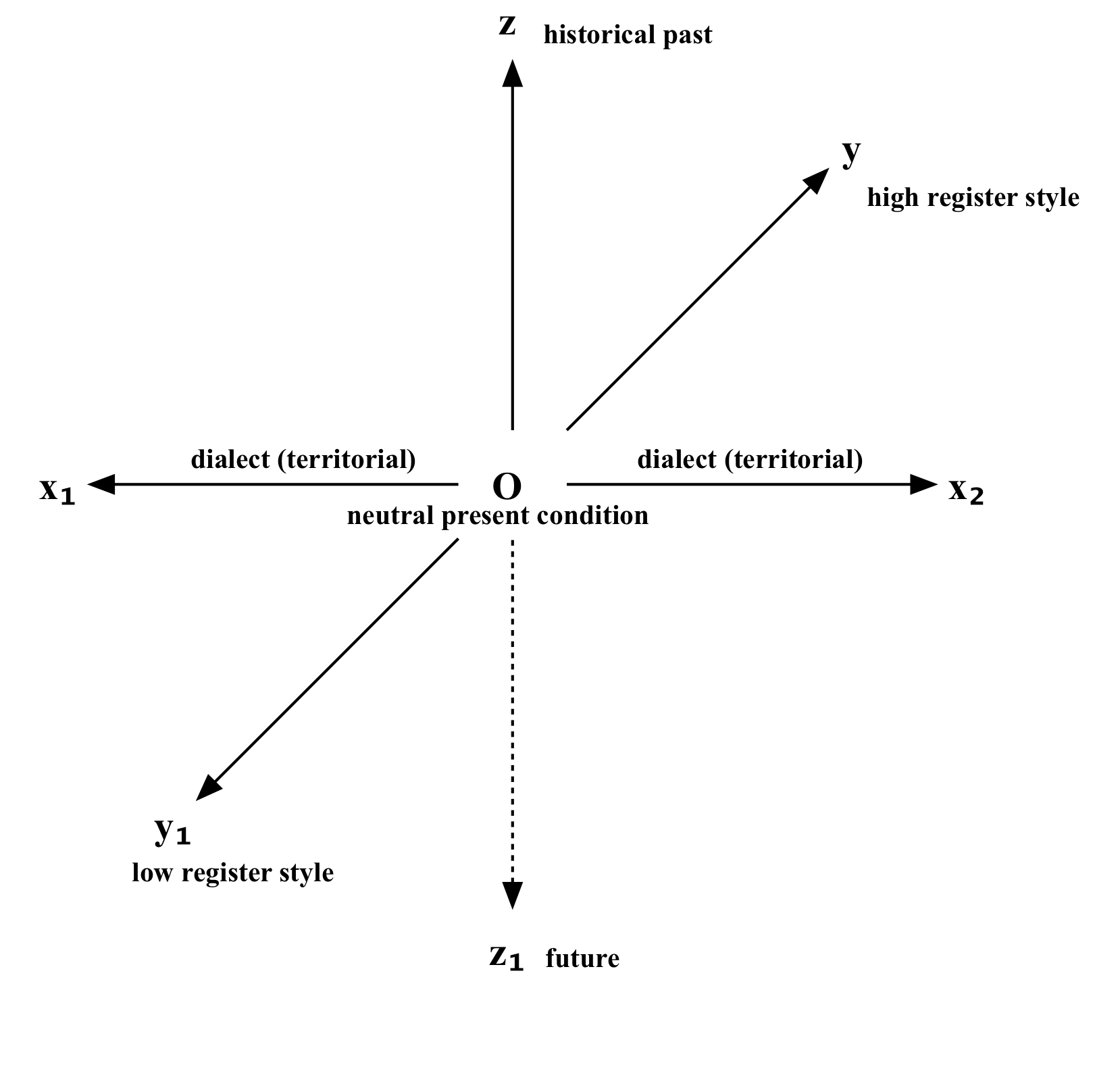
Diagram 1. Variations in language, based on Avanesov, et al. (Avanesov 5).
Why is it important to algorithmically model Slavic spelling variations, both modern and pre-modern? Doing so provides a technical tool to study texts in a broad sense, for example, performing searches on texts that have divergent spelling, separated by boundaries of script, language, and style. It is, therefore, necessary to model and generalize these spelling tendencies, and produce an algorithm which can produce these spelling variations.
In the context of various language traditions, algorithms exist for simplifying searches, such as Soundex and Megaphone for English. Some of these, have limited applicability to Slavic languages, such as Daitch–Mokotoff Soundex. Nevertheless, their approach is needlessly broad, considering non-Slavic linguistic features, and is also limited by targeting the Latin script only. Therefore, a new algorithm addressing the problem is necessary.
We have attempted to programmatically solve this by modelling the variations so that access to both modern and pre-modern Slavic spelling variations across language, script, and style lines, becomes possible.1
Consider the following task: a search is to be conducted for the name Jaroslav Dědov, to see if it appears in a large corpus of Slavic texts of various time periods and languages. Using a specific programmatic solution that considers diachronic spelling variations, we can search for a variety of forms which increases the number of positive matches. Ordinary searching using fuzzy matching just won't do, because we need to span writing systems, phonetic as well as etymological spelling, and account for the variety of changes which have taken place and affect the actual use of the word. Using our algorithm, we get the following results: Ярослав Дедов → [ⱗⱃⱁⱄⰾⰰⰲⱏ ⰴⱑⰴⱁⰲⱏ, рославъ Дѣдовъ, Ѧрославъ Дѣдовъ, Ярославъ Дѣдовъ, Ярослав Дзедов, Jarosłav Dziedov, Jaroslav Dedov, Jaroslav Djedov, Jaroslav Dijedov, Jaroslav Dědov, Jaroslav Diedov, Jarośław Dedow].
While spelling in all Slavic languages came to be standardized in the last few centuries, we can observe in texts before this period a much greater freedom as regards to spelling. These styles can be generally described as having several competing vectors: a reverence for older models versus a modelling on local patterns of speech, and a desire for intentional divergence versus a conflation with, the style of dialectical neighbours. These tendencies can be seen even today, as reformers and prescriptive spellers appeal to one or the other, depending on their stylistic allegiances.
Attached to political processes, these linguistic variations in spelling, often with accompanying changes in prescribed grammars and preferred lexemes, have at times given rise to the development and establishment of separate Slavic languages. Because of this political aspect, the spelling variations, once common before the era of nation states, became entrenched in prescriptive ways unimagined by the medieval scribe. Therefore, modelling Slavic languages before the era of nation states means removing oneself from anachronistic borders of today’s Slavic languages, and evaluating texts in which it is not possible to clearly identify as belonging to any particular modern language, but it is rather necessary to speak of differing tendencies of Slavic, no matter the particular geographic location or native dialect of the author are.
Using programmatic means, it is possible to define these vectors and tendencies, along with regional flavours, and produce in an automated fashion, multiple variations of spellings. What is the significance of having access to these programmatically reconstructed spelling variations? As texts become digitized, it becomes increasingly important to be able to search them. The myriad of spellings of pre-modern Slavic authors make doing so with the existing tools difficult. An examination of any page from the interlinear collated edition of fundamental source text of East Slavic history, the Povest’ vremennyh let (PVL), illustrates the difficulty (OSTROWSKI, 1999).
While the study of the PVL has focused on identifying the best, or original version of the text, and the spelling variations themselves sometimes studied, they have not, to our knowledge, been modelled, nor has it been possible to search across the narrow confines of modern Slavic national borders to compare words with other pre-modern texts, perhaps of the Western Slavic tradition, in any meaningful way. Something as simple as word search is still impossible across Slavic modern languages, and especially across historic textual data, which contains variations in spelling now considered obscure.
Solving this problem algorithmically is a step forward for working with various textural data in Slavic languages, from searches of an author’s name in library catalogues, to literary studies based on large corpus data sets.
Literature
AMBROSIANI, P. Internal Analysis of Church Slavonic Orthography. Studies in Slavic and General Linguistics 23. 1996, p. 1–20.
AVANESOV, R. I. et al. Lingvisticheskai͡a geografii͡a i struktura i͡azyka. O prit͡sipakh obshcheslavi͡anskogo lingvisticheskogo atlasa. Moscow: Akademii͡a Nauk SSSR. 1958.
CHACHULSKA, B. Korpusy Komputerowe Języków Słowiańskich. Studia Z Filologii Polskiej I Słowiańskiej 40. 2005. p. 483–507. [online]. [17.06.2017]. Available on: < https://polona.pl/item/38111501/>.
DOMBROWSKI, A. When is Orthography Not Just Orthography? The Case of the Novgorod Birchbark Letters. Annual Meeting of the Berkeley Linguistics Society 36.1. 2010, p. 91 – 100. [online]. [30.09.2016]. Available on: <http://journals.linguisticsociety.org/proceedings/index.php/BLS/article/view/3904>.
HUSIC, G. Russo‐Serbian Orthography: Cataloging Conundrum and a Proposed Solution. Slavic & East European Information Resources 10.1. 2009. p. 45–60.
MAXWELL, A. Literary Dialects in China and Slovakia: Imagining Unitary Nationality with Multiple Orthographies. International Journal of the Sociology of Language 164. 2003, p. 129–49. [online]. [30.05.2017]. Available on: < https://www.degruyter.com/view/j/ijsl.2003.2003.issue-164/ijsl.2003.051/ijsl.2003.051.xml >.
OSTROWSKI et al. Povest Vremennykh Let: an Interlinear Collation and Paradosis. Cambridge: Harvard University. 1999.
SCHWARTZ, E. The Language of the Earliest East Slavic Charters (XII-XIII C.): Orthography and Inflectional Morphology (2008): ProQuest Dissertations and Theses. [online]. [30.04.2017]. Available on: <http://www.worldcat.org/title/language-of-the-earliest-east-slavic-charters-xii-xiii-c-orthography-and-inflectional-morphology/oclc/23995922>.
SONNENHAUSER, B. – FUCHSBAUER, J. Corpus-based analysis of changing norms: tracing the life of Petka Tărnovska from Middle Bulgarian Church Slavonic to Balkan Slavic. In: Textual Heritage. 2014. [online]. [16.05.2017]. Available on: <https://www.academia.edu/7828829/Corpus-based_analysis_of_changing_norms._Tracing_the_Life_of_Paraskeva_of_T%C4%83rnovo_from_Middle_Bulgarian_Church_Slavonic_to_Balkan_Slavic_Fuchsbauer_and_Sonnenhauser_>.
YOO, S. M. A Corpus-linguistic Analysis of Fifteenth- and Sixteenth-century Rjazanian Legal Documents (2001): ProQuest Dissertations and Theses. Ohio: Columbus. 2001. [online]. [17.05.2017]. Available on: <https://etd.ohiolink.edu/pg_10?0::NO:10:P10_ACCESSION_NUM:osu1486400446369876>.
ZALIZNJAK, A. A. Drevnenovgorodskij dialekt. Moscow: Jazyki slavjanskoj kul’tury. 2004.
ŽIVOV, V. M. Norma, variativnost’ i orfografičeskie pravila v vostočnoslavjanskom pravopisanii XI-XIII veka. In: ŽIVOV, V. M. (ed.) Vostočnoslavjanskoe pravopisanie XI-XIII veka. Moscow: Jazyki slavjanskoj kul'tury. 2006, p. 9–76.
Danslav Slavenskoj – absolvent Harvardovy univerzity. V současné době doktorand slavistiky na katedře rusistiky a východoevropských studií na Univerzitě Komenského v Bratislavě.
Kontakt: danslav.slavenskoj@uniba.sk
[1] A working version of the algorithm can be accessed at http://slavenica.com/.
Mohlo by vás z této kategorie také zajímat
- Polská nebinární poezie a nastínění problematiky překladu (Dagmar Haladová)
- Различията в метафорогенните способности на езика – предизвикателства пред преводача (Диляна Денчева)
- Ti, kdo zaseli jedovaté býlí... (Dana Ferenčáková)
- Literatura a čas: Konstantin Simonov (Ivo Pospíšil)